
Senior Solution Architect
Aug 24, 2023 | 7 mins read



Due to the rapid emergence of, and advancements in, cloud computing, the dual concepts of containerization and virtualization have gained significant prominence. These technologies have revolutionized the way we deploy, manage, and scale software applications and infrastructure. The cloud-native model is one such example. Software applications that were traditionally monolithic in nature, cannot remain in their historical format when migrated to the cloud. Virtualization in its pure form does not fit the monolithic architecture.
Before we proceed, let’s briefly examine the twin theories of virtualization and containerization, using virtual machines and containers as a practical foundation for each.
Virtualization and Containerization
According to the research paper "Virtualization Approach: Theory and Application," the theory and practice of virtualization, still in use today, was developed in 2016. It utilizes computing resources efficiently by employing software that builds, deploys, and runs any number of virtual machines (VMs) on top of physical computer servers, reducing the amount of hardware infrastructure required, thereby reducing costs and increasing operational efficiencies.
Juxtapositionally, containerization involves using lightweight containers (such as Docker containers) to package a software application or individual parts of the application if divided into microservices.
Containers and virtual machines are allied to virtualization; however, they represent different strategies (and methodologies) within the broader virtualization landscape. While both aim to abstract and isolate computing resources, they have distinct characteristics and use cases.
While an in-depth discourse on the individual characteristics and uses of containers and virtual machines is not in the scope of this text, let’s look at a few points for they become relevant when providing the argument for why containerization is the ideal vehicle for packaging, deploying, and executing cloud-native applications.
Containers: A Brief Summarization of their Characteristics and Uses
In summary, containers have the following characteristics. They are:
- lightweight because they share the host’s operating system’s kernel;
- highly efficient in terms of resource usage;
- portable, packaging applications and their dependencies, ensuring consistency across different platforms and operating systems; and
- highly scalable, to rapidly deploy multiple instances of a containerized application simultaneously to handle varying workloads.
Some of the most common containerization use cases include:
- deploy cloud-native applications;
- package applications to deploy across different platforms; and
- CI/CD (continuous integration/continuous deployment) pipelines
Virtual Machines: A Brief Summarization of their Characteristics and Uses
As with containerization’s list of characteristics and uses, virtual machines also have their own list of attributes and uses, with the following being the most significant:
- run complete, individual operating systems;
- total isolation from other operating systems;
- run different operating systems (such as different Windows and Linux variants); and
- have significantly more resource overhead requirements than containers because they include complete operating system instances and are managed by a hypervisor.
Lastly, the most common use cases include:
- execute legacy software;
- develop applications for different platforms; and
- manage potential malware safely and securely.
Utilizing Containerization to Scale Cloud-Native Applications
Containerizing modern cloud-native applications results in lightweight, efficient, and portable containers containing application modules (or microservices) that can be deployed, orchestrated, and scaled according to the varying workload demands that are a significant part of the modern cloud-computing landscape.
As inferred throughout this discussion, the ability to scale a cloud-native application is imperative.
Why is scaling a cloud-native app mandatory and how is it achieved?
The “Hows” and “Whys” of scaling Cloud-Native Apps
By way of answering these questions, let’s consider the following points:
1. Why Must Cloud-Native Applications be Scaled?
The first point to discuss is the imperative of scaling cloud-native applications. In other words, why is it so important to ensure that these apps can be scaled not only up but also down again?
The concise answer to this question is that workloads served by cloud-native applications are often highly variable, diverse, and unpredictable.
For instance, imagine you run an eCommerce site that participates in online sales like Black Friday and Cyber Monday. And the user traffic to your site is very heavy on these sale days but extremely light compared to other days of the year. Additionally, traffic is the lightest during the months of January and February, when consumers traditionally do not spend any money, especially after Thanksgiving and the festive season.
To put these statements into perspective, 2021 Black Friday statistics quoted by Radovan Sekulic of MoneyTransfers.com report that:
- 88 million Americans shopped online on Black Friday 2021.
- Americans spent a total of $8.9 billion online on Black Friday 2021.
- Black Friday was the busiest day of the 2021 cyber weekend.
Therefore, as an eCommerce site owner, you have a choice to make:
- run your eCommerce site with the resources needed to handle the heaviest workloads all year round; or
- run your eCommerce site with the resources required to handle the lightest workloads all year round; or
- scale your site’s resources up and down throughout the year based on workload requirements.
Implementing either of the first two options is not a good idea. The first option, running a resource-intensive application when not needed, is not efficient and cost-effective. Your site’s user experience will not be negatively affected, but the cost of running the site will unnecessarily increase operating costs, reducing operational efficiencies.
Juxtapositionally, the second option, running a resource-light application all year round, is also not efficient and cost-effective. Your site’s user experience will be heavily compromised when the workload requirements are the highest, increasing the bounce rate, driving customers away when it matters most, and losing income, possibly driving you out of business.
The third option, scaling your site’s resources up and down as required, is the
only choice. It ticks all the boxes regarding optimizing resources as the
workload increases and decreases, driving sustainable business growth and income
over time.
2. How are Cloud-Native Applications Scaled?
Finally, we have reached the raison d’etre of this content, or how to scale a cloud-native application.
Kubernetes is the container orchestration platform that DevOps engineers most often use to deploy, orchestrate, and maintain containerized applications with a microservices-based architecture.
Statistics quoted by Enlyft.com report that 79,595 companies across the globe use Kubernetes with a market capitalization as follows:
- 70% of organizations have a market cap of less the $50M.
- 17% are large enterprises with a market cap of greater than $100M.
- 13% are medium-sized organizations with a market cap between $50M and $100M.
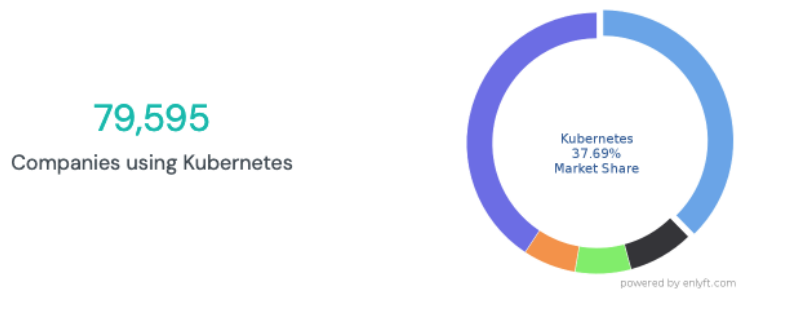
Source: Enlyft.com
Note: Scaling containerized applications is not the only function Kubernetes facilitates (and automates). But it is the topic we are currently concerned with; therefore, let’s dive in and focus on the broad strokes of scaling cloud-native applications.
Kubernetes: Scaling Cloud-Native Applications
Before we look at an overview of how Kubernetes scales containerized applications, let’s quickly consider the difference between scaling and autoscaling applications.
Scaling vs. Autoscaling Containers
The article titled, “How do you test and optimize your autoscaling and manual scaling policies and configurations?” notes the following:
“Autoscaling and manual scaling are two common methods to adjust the capacity of your cloud-based applications and services in response to changes in demand.”
The most significant (and often only) difference between the two is that manual scaling is human-operator-driven, while autoscaling is machine-driven. In practice, Kubernetes automatically scales resources up and down based on the configurations created by DevOps engineers or Kubernetes administrators.
As with everything in life, there are advantages and disadvantages to both methods.
1. Manual Scaling
You have more control and flexibility over the resources you can allocate to your containerized application. This is useful when the changing workload demands are planned and predictable. However, at the same time, implementing manual scaling requires careful thought and planning as it requires human intervention and monitoring, increasing the risk of human error.
2. Autoscaling
As described above, autoscaling uses configurations that provide Kubernetes with the information it needs to scale resources up and down as the network (or user) traffic increases and decreases respectively.
This fact is in itself both an advantage and disadvantage. It is advantageous because human intervention is not required to manually scale the needed resources, resulting in efficient resource utilization, high availability, predictability, cost-effective use, and improved application performance.
At the same time, adopting autoscaling methods is disadvantageous because of the complex nature of the configuration scripts, operational overheads, scaling limits, and resource contentions.
The Three Types of Autoscaling
Even after describing the disadvantages of using autoscaling in Kubernetes to automatically manage resource allocations based on the variable application workloads, it is beneficial to automate the scaling functions rather than doing it manually.
Kubernetes provides three types of autoscalers, each designed to address specific scaling requirements and scenarios:
1. Horizontal Pod Autoscaler (HPA)
The Horizontal Pod Autoscaling (HPA) is defined in the research paper, “Horizontal Pod Autoscaling for Elastic Container Orchestration,” as:
“A seamless service by dynamically scaling and up and down the number of resource units, called pods, without having to restart the whole system.”
Horizontal scaling is the most common method of autoscaling in Kubernetes, allowing you to automatically adjust the number of available pod replicas based on CPU or memory utilization metrics. When the resource utilization exceeds or falls below defined thresholds (as defined in the configurations), the HPA will either increase (scale out) the number of pods in use or scale in (decrease) the number of pods in use, continuously maintaining the requisite resource utilization levels.
2. Vertical Pod Autoscaler (VPA)
Instead of scaling the number of replica pods to handle variable workloads, the Vertical Pod Autoscaler (VPA) automatically scales the CPU and memory within an individual pod. In other words, vertical scaling scales out the internal resources used by a single pod as the workload increases and scales in the CPU and memory allocated to a pod when the workload decreases, ensuring that the pods always receive the correct number of resources to avoid over- or under-provisioning.
While this method has its place in the Kubernetes autoscaling ecosystem by optimizing resource utilization within existing pods, its most significant disadvantage is that to adjust these resources, the affected pod must be stopped and restarted, potentially resulting in the application failing.
3. Cluster Autoscaler (CA)
The Kubernetes Cluster Autoscaler (CA) scales the application in or out by adjusting the number of nodes in a cluster based on resource requests from pods. The biggest difference between this autoscaler, the HPA, and the VPA is that it does not scale pods or pods’ resources in or out; it automatically adjusts the size of the Kubernetes cluster by adding or subtracting worker nodes based on resource utilization, ensuring the cluster can manage the varying workloads.
In Conclusion
The ability to scale cloud-native applications manually or automatically is a fundamental requirement, not a “nice-to-have” in the modern cloud computing landscape. The primary vehicles used as the foundation for scaling cloud-native apps are containers and container orchestration platforms such as Kubernetes.
Working backward, the development of containers and their orchestration platforms would only be where they are today with the conceptualizations of containerization and virtualization, together with their application in the form of containers and virtual machines.





















