
Product Strategy Lead
Sep 10, 2022 | 4 mins read



Scaling containerized applications and managing infrastructure resources effectively using Kubernetes, the de facto container orchestration platform, is critical to the modern computing environment. Suffice to say, the cloud-native computing model would not be as successful as it is without Kubernetes’ ability to effectively orchestrate, coordinate, deploy, and manage containerized applications.
Before we dive into scaling applications and managing resources effectively with Kubernetes, let’s remind ourselves what K8s is:
The authors of the research paper, Balanced Leader Distribution Algorithm in Kubernetes Clusters, describe K8s as a popular open-source project providing an orchestration platform for containerized applications and helping these applications achieve high scalability and availability.
2020 statistics quoted by the Cloud Native Computing Foundation report that:
“Kubernetes is being used for container orchestration by more than 71% of Fortune 100 companies.”
High Scalability and Availability
But first, let’s answer these questions:
- What is high scalability and availability?
- Why is it so important in the modern cloud-native paradigm?
High scalability refers to a system’s ability to handle increased workloads and growing demand without sacrificing performance. It involves the capability to accommodate larger amounts of traffic, data, or users by adding resources as needed. In the Kubernetes context, scalability can be achieved by distributing the workload across multiple nodes, utilizing load balancing, and optimizing resource allocation.
High availability, on the other hand, describes a system’s ability to remain operational and accessible even in the event of failures or disruptions by designing the system so that if one component fails, another takes over seamlessly to ensure uninterrupted service. Redundancy, failover mechanisms, and effective disaster recovery strategies are crucial to achieving high availability.
In the modern cloud-native paradigm, high scalability and availability are of paramount importance for several reasons, the most important being:
- Dynamic workloads: Cloud-native applications experience varying levels of traffic and demand. High scalability allows these applications to handle sudden spikes in traffic without degradation of performance.
- Elasticity: The ability to dynamically scale resources up or down is crucial to manage changing workloads efficiently. Cloud-native applications can automatically adjust to demand fluctuations.
- Resilience: High availability ensures that applications remain accessible even when components fail or experience issues.
- Customer experience: Modern users have high expectations for application performance and availability. A service outage or slowdown can result in negative user experiences leading to dissatisfaction and potentially lost business.
- Competition: In today’s competitive landscape, organizations need to provide reliable, responsive, and always-available services to stay ahead of competitors.
- Adaptability: Cloud-native applications often undergo frequent updates and deployments. High scalability and availability support these continuous changes without causing downtime.
- Efficient resource utilization: Scalability allows organizations to allocate resources based on demand, avoiding over-provisioning and optimizing cost efficiency.
- Disaster recovery: High availability strategies, including data replication and geo-distribution, ensure that applications can recover quickly from disasters or outages.
Not only is achieving high availability and scalability in a cloud-native application imperative to organizational success, but we also need to add another concept to this discussion in the form of the word "constant." Cloud-native applications must be scalable and highly available constantly.
Therefore, considering all this information, the next question to ask and answer is how do we constantly achieve high availability and scalability in a cloud-native application?
The simplest, but not most effective, answer is to employ DevOps teams to implement these principles and mandates manually. However, this is virtually impossible to achieve 24/7, 365 days a year. A far better option is to revisit this text's opening statements and utilize Kubernetes to automate the processes needed to ensure that a cloud-native application is constantly scaled and highly available.
Scaling Applications and Managing Resources with Kubernetes
Before we consider a practical use case of scaling applications and managing resources using K8s, it is worth noting that the scaling application utilizes resource management. These two concepts are intertwined with each other. Therefore, to simplify this topic, let’s discuss managing infrastructure resources within the principles of scaling applications.
Moreover, it is often assumed that when we talk about scaling applications, we mean scaling up applications to handle the increased demand. However, scaling an application down again after this additional demand decreases is equally important.
The purpose and function of scaling is to ensure efficient resource utilization and cost savings as resource demand increases and decreases over time. Kubernetes provides mechanisms to scale up and down, allowing applications to adapt to changing workloads while maintaining resource and cost efficiencies.
The reasons for carefully managing infrastructure and software resources are interlinked and multifold, including:
- Performance consistency: Running too many instances of the application can lead to contention for resources, affecting the performance of this and other applications. Scaling up and down based on demand maintains consistent performance.
- Resource optimization: Harnessing and releasing resources as needed allows these resources to be allocated to other applications or services, maximizing overall resource utilization.
- Environmental impact: The impact of using resources unnecessarily is becoming increasingly apparent and is having a greater impact on our environment. Therefore, efficient resource utilization is not only financially beneficial but also reduces the environmental impact associated with unnecessary compute resources.
- Cost efficiency: Using unnecessary resources consumes cloud resources, increasing costs. Scaling up/down as needed helps avoid overprovisioning and reduces infrastructure expenses.
Using Kubernetes to Scale Applications: A Use Case
In practice, scaling applications up and down in K8s involves adjusting the number of replicas (pods) for a deployment, replica set, or stateful set to meet the changing resource demands. Kubernetes provides mechanisms to scale applications up/down or increase/decrease the number of replicas based on criteria like CPU utilization, custom metrics, or user-defined rules.
For instance, assume you have an eCommerce website that experiences varying traffic throughout the day. During peak shopping hours, the site receives a high number of visitors, requiring more resources, and vice versa.
Here is a step-by-step guide to use K8s to manage infrastructure and application resources by scaling resources up/down as required:
1. Application Containerization
Modernize your current application using the microservices architecture and package individual microservices into a separate container, resulting in any number of containerized microservices.
2. Application Deployment
Deploy this application on Kubernetes using a Deployment, ensuring the app is always running and maintains a specific number of replicas.
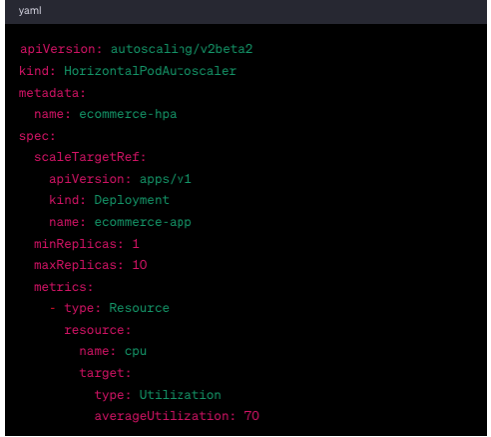
3. Horizontal Pod Autoscaling (HPA)
As the following code snippet describes, set up HPA for your deployment to automatically scale the number of replicas based on CPU utilization. During peak hours, when CPU usage crosses a certain threshold, HPA will scale up the replicas to meet the demand and back down again when the demand drops.
4. Cluster Autoscaler
Enable the Cluster Autoscaler to manage node scaling. When the HPA triggers scaling up, the Cluster Autoscaler ensures enough nodes to accommodate the additional pods.
5. Resource Requests and Limits
Set appropriate resource requests and limits for your pods. This helps Kubernetes allocate resources effectively and prevent resource contention.
6. Monitoring and Alerts
Use monitoring and alerting tools like Prometheus and Grafana. Set up alerts to notify you when CPU utilization crosses a certain threshold.
In Conclusion
Managing resources by scaling an application using Kubernetes’ Horizontal Pod Autoscaling based on demand allows an application to dynamically scale up to handle increased traffic during peak hours and down during off-peak hours to save costs and resources. Kubernetes’ scaling mechanisms and efficient resource management provide the flexibility required for modern cloud-native applications.

















